
文中摘自微信公众平台「超级程序员」,创作者超级程序员 。转截文中请联络超级程序员微信公众号。
监控系统软件是运维管理管理体系乃至全部手机软件生命周期中最重要的一环,健全的监控可以协助大家事先及时处理常见故障,过后迅速查证精准定位。而在以dubbo为象征的云原生架构管理体系中,系统软件分成好几个层级,服务项目中间启用链接繁杂,系统软件中必须监控的目的十分多,要是没有一个健全的监控系统软件就很难确保总体服务项目的连续平稳。
监控目标及分层次
在具体情景中监控系统软件依照监控的目标及系统软件结构分析,从底向上可以先后区划为基本层、内层、网络层、业务层等好几个方面的监控。实际可如下图所示:

基本层监控便是对主机服务器(包含宿主机、器皿)以及最底层資源开展监控,以确保运用程序执行所依靠的基本自然环境的平稳运作。基本层监控关键有两个方位:
- 資源运用:是对像I/O使用率、CPU利用率、运行内存利用率、硬盘利用率、互联网负荷等那样的硬件平台开展监控。防止因应用软件自身或其他特殊情况导致的硬件平台耗光而发生的服务项目常见故障。
- 通信网络:是对服务器进行的网络状态开展监控。通信网络是互联网技术的关键根基,假如服务器中间的互联网发生如延迟时间过大、丢包率高那样的网络问题,可能严重影响业务。
必须表明的是,在根据Kubernetes容器化技术性的新式云原生基础设施建设中,基本层的监控不但要对宿主机自身开展监控,也需要对Kubernetes集群情况以及器皿資源应用状况开展监控。这在后面大家搭建根据Kubernetes的基本层监控管理体系时可能详细详细介绍。
内层监控关键指的是对例如Nginx、Redis、MySQL、RocketMQ、Kafka等业务系统所依靠的分布式数据库手机软件的监控,他们的稳定性也是确保应用软件不断可以用的重要。一般来说特殊的分布式数据库手机软件都是会依据自己特性搭建目的性的监控管理体系。
网络层监控这儿是指对业务性系统服务的监控,一般来说大家对应用软件监控的侧重点关键反映在下述一些层面:
- HTTP插口要求浏览。包含插口反应时间、货运量等;
- JVM监控指标。针对Java服务项目,还会继续重点关注GC時间、连接数、FGC/YGC耗时等JVM特性有关的指标;
- 資源耗费。应用软件布署后会耗费一定的資源,例如应用软件对运行内存、CPU的损耗状况;
- 服务项目的身心健康情况。例如现阶段服务项目是不是生存,运作是不是平稳等;
启用链接。在分布式架构中,因为启用链接拉长,还必须关键监控服务项目间的启用关联和启用状况,防止部分上中下游服务项目间的链接常见故障引起系统软件全面性山崩;
业务层监控也是监控系统软件所关心的一个关键內容,在具体情景中假如你仅仅让应用软件平稳运作那肯定是还不够的。因而,大家时常会对实际业务造成的信息开展监控,例如网站程序所关心的PV、UV等主要参数;后面如买卖之类的系統大家则会关心订单信息量、通过率等。
业务指标也是反映系统软件可靠性的关键因素。一切系统软件,假如发生了问题,最开始遭受危害的肯定是业务指标。针对关键业务指标的调整因实际的业务和情景而异,因此针对业务层的监控必须搭建具有业务特性的业务监控系统软件。
普遍的监控指标种类
在指标类监控系统软件中,根据统计分析指标可以理性地认知到整体体系的运作状况。发生问题后,每个指标会最先发生起伏,这种起伏会体现出系统软件是这些层面出了问题,进而可以由此清查产生问题的缘故。下边让我们各自看来下统计分析指标究竟有什么种类,及其常用的统计分析指标都有哪些,它是大家进一步了解指标类监控系统软件的基本。
从总体上看,普遍的Metrics指标种类具体有:计数器(Counter)、检测仪(Gauge)、条形图(Histogram)、引言(Summary)这四类。他们的特性各自如下所示:
1. 计数器(Counter)
计数器是一种具备累积特点的指标种类,一般这一数值Double或是Long种类。例如常用的统计分析指标QPS、TPS等的值便是根据计数器的方式,随后相互配合一些统计分析函数计算得到的。
2. 检测仪(Gauge)
表明某一时间点,对某个标值的精确测量。检测仪和计数器都能够用于查看某一时间点的确定內容的标值,但和计数器不一样,检测仪的值可以随便转变,可以提升还可以降低。例如获得Java线程池中活泼的连接数,应用的是ThreadPoolExecutor中的getActiveCount方式;除此之外,也有较为普遍的CPU使用率、内存占用量等实际指标全是根据检测仪获得的。
3. 条形图(Histogram)
直方图是一种将好几个标值汇聚在一起的算法设计,可以表明信息的划分状况。例如以普遍的回应耗时举例说明,可以把回应耗时数据信息分成好几个桶(Bucket),每一个桶意味着一个耗时区段,例如0~100ms、100~500毫秒,依此类推。根据那样的方式,可以更直观地见到一个时间范围内的要求耗时遍布,这将有利于人们了解耗时状况遍布。
4. 引言(Summary)
摘要与条形图相近,表明的也是一段时间内的信息結果,可是引言反映的数据信息內容不太一样。引言一般用以标志分位值,分位值实际上也是大家常说的TP90、TP99等。例如有100个耗时标值,将全部的标值从低到高排序,取第90%的部位,这一位子的值便是TP90的值,假如这一桶相匹配的值假定是80ms,那麼就意味着不大于90%部位的要求都≤80ms。
Kubernetes微服务架构监控管理体系
前边大家从总体上叙述了监控系统软件分层次及其了解指标类监控系统软件所必须熟练掌握的几种常用的指标种类。下面大家关键讨论根据Kubernetes的微服务架构监控管理体系。
从监控目标及系统软件分层次的角度观察,监控系统软件必须监控的标准是十分普遍的,但从微服务架构监控的方面而言,假如你的微服务架构布署彻底是根据Kubernetes云原生自然环境的,那麼大家必须特别关注的监控目标关键便是Kubernetes集群自身及其运作在其中的微服务架构运用器皿。例如对容器資源应用状况,如CPU使用率、运行内存利用率、互联网、I/O等指标的监控。
自然,这并不是说像基本层的物理机、vm虚拟机机器设备或是内层手机软件的监控大家无需关心,仅仅这一部分工作中一般会出现专业的工作人员去维护保养。而假如采用的是云服务器,那麼云服务器生产商大多数早已为大家出示了监控适用。除此之外,针对基本mac层及绝大多数正中间手机软件的监控并非文中所要体现的关键,因此也就不会再做太多的实践活动,大伙儿对于此事有一个全局性的了解就可以。
而返回以Kubernetes为媒介的微服务架构监控管理体系,尽管以前Kubernetes新项目的监控管理体系比较复杂,小区中也有很多计划方案。可是这套管理体系发展趋势到今日,早已彻底转变成了以Prometheus新项目为关键的一套统一计划方案。在这节的具体内容中大家就将演试怎样紧紧围绕Prometheus来搭建对于Kubernetes的微服务架构监控系统软件。
1. Prometheus介绍
通过领域很多年的实际和沉积,现阶段监控系统软件按完成方法关键可以分成四类:1)、根据时间序列分析的Metrics(衡量指标)监控;2)、根据启用链的Tracing(链接)监控;3)、根据Logging(日志)的监控;4)、身心健康物理检查(Healthcheck)。而在以上几类监控方法中Metrics监控是当中最首要的一种监控方法。
简易了解Metrics的表达形式,便是在离散变量的时间点上形成的标值点[Time,Value],由某一指标构成的一组[Time,Value]标值点编码序列也被称作时间序列分析,因此Metrics监控也经常被称作时间序列分析监控。
如上所述,大家简易论述了指标系统软件的主要特性,而下面要介紹的Prometheus便是一款根据时间序列分析的开源系统Metrics种类的监控系统软件,它可以很便捷地开展统计分析指标的储存、查看和报警。从总体上看Prometheus的体系结构,如下图所示:
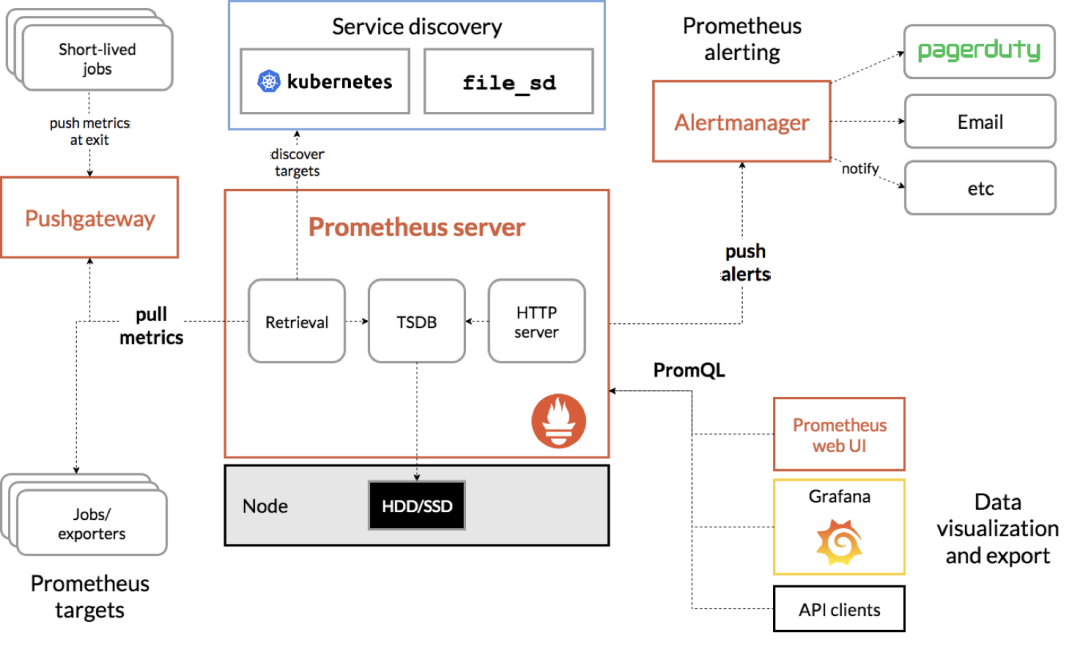
从上面中可以看得出,Prometheus工作中的关键,主要是应用Pull(获取)的方式去搜集被监控目标的Metrics数据信息(监控指标数据),随后由Prometheus网络服务器将受到的指标数据信息开展汇聚后存放到TSDB(时间序列分析数据库查询,例如OpenTSDB、InfluxDB)中,便于后面依据時间随意查找。
拥有这套关键体制,Prometheus剩余的部件就主要是用于相互配合这套体制运作的了。例如PushGateway,它可以可以被监控目标以Push的形式向Prometheus消息推送Metrics数据信息。而Alertmanager,则可以依据Metrics信息内容灵便地设定警报。
除此之外,Prometheus还带来了一套完善的PromQL数据库架构,根据其供应的HTTP查看插口,使用人可以很便捷地将指标数据信息与Grafana(数据可视化监控指标展现专用工具)结合在一起,进而灵便地订制归属于系统软件本身的重要指标监控Dashboard(生产流程卡)。
2. Prometheus Operator安装布署
前边大家简易讲解了Prometheus监控系统软件的基本概念,下面的信息将以实际操作的方法演试怎么使用Prometheus搭建一套对于Kubernetes集群的微服务架构监控管理体系。
在具体的应用领域中,对于不一样的监控目标Prometheus的实施方法也会各有不同。例如要监控的另一半是最底层的物理机,或是以物理机方法布署的数据库查询等分布式数据库系统软件,那麼这样的情况下一般也会将Prometheus监控系统软件的布署自然环境置放在物理机下。
而假如对于的是Kubernetes集群的监控,那麼如今主要的形式是选用Promethues-Operator将Promethues布署到Kubernetes集群当中,那样可以更原生态的形式执行对Kubernetes集群及器皿的监控。这儿所讲的Promethues-Operator 就是指针对Kubernetes的Promethues封装形式包,它可以简单化Promethues的布署和配备。
下面让我们实际演试怎样根据Promethues-Operator在Kubernetes中迅速安裝布署Promethues(Kubernetes试验自然环境可参照本栏目相关内容),操作步骤如下所示:
1)、安裝Helm
在此次安裝流程中,将应用到Kubernetes的包可视化工具Helm。Helm是Kubernetes的一种包管理工具,与Java中的Maven、NodeJs中的Npm及其Ubuntu的apt和CentOS的yum相近。关键用于简单化Kubernetes对使用的布署和管理方法。
最先从Github下载相对应的Helm安装文件,实际指令参考如下所示:
缓解压力,并将下载的可执行Helm文档拷贝到文件夹名称/usr/local/bin下,指令如下所示:
以后执行helm version,假如能见到Helm版本信息内容,就表明Helm手机客户端安裝成功了,详细如下:
安装完Helm手机客户端后,因为一些公共性Kubernetes包是在远程控制库房中监管的,因此还要加上helm charts(Helm中的Kubernetes安装包又叫charts)官方网库房,指令如下所示:
查询当地helm库房是不是加上取得成功,指令如下所示:
这时,查询Helm库房就能见到各种各样模块的charts目录了,指令实际效果如下所示:
如上所显示,这时根据“helm search”指令就可以查询到各种各样stable版本的Kubernetes安装包了!
2)、Helm检索Prometheus-Operator安装包
在实际安裝Prometheus-Operator以前,大家首先用“helm”指令检索Prometheus有关的charts包,指令如下所示:
$ helm search repo prometheus
实际百度搜索如下图所示:
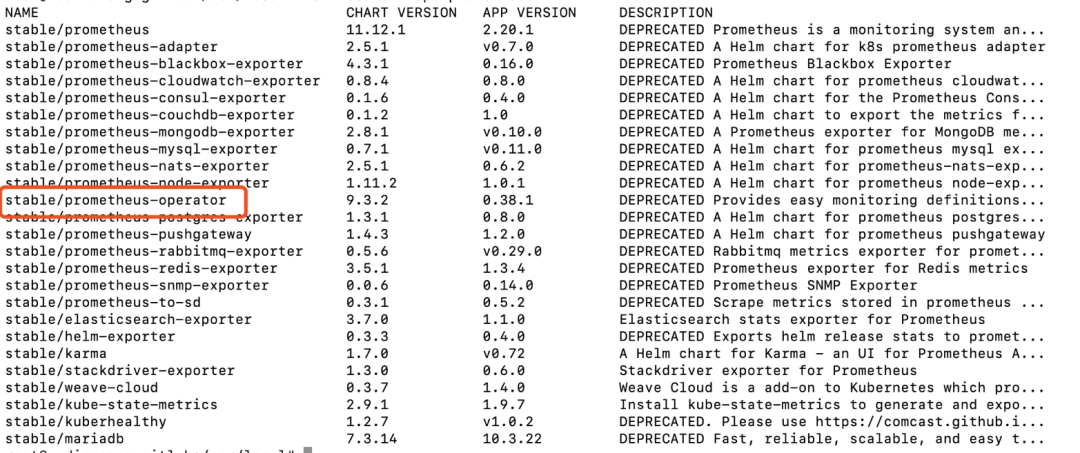
如下图所示所显示,我们可以见到Helm库房中可以检索到版本为0.38.1的“stable/prometheus-operator”的安装文件。下面就可以根据helm实际安裝了!
3)Helm安装Prometheus-Operator监控系统
下面啊,根据Helm实际安裝prometheus-operator监控系统,指令如下所示:
执行安装指令后,輸出結果如下所示:
实行完安裝指令后,查询详细的Kubernetes Pods信息内容,指令如下所示:
如上所显示,能够看见Prometheus监控系统有关的部件都以Pod的形式运转在了Kubernetes集群中。
Prometheus监管实际效果演试
根据之前的操作过程,大家根据Helm的方法早已将Prometheus Operator安装包布署在了Kubernetes集群当中。而此时此刻的Prometheus事实上就己经逐渐充分发挥,并收集了各种Kubernetes的运作指标值信息内容。可以根据Promethues内嵌的监控界面对于此事开展查询,操作步骤如下所示:
查询Kubernetes中查看内嵌监控界面所属的Pod连接点,指令如下所示:
应用nodeport方法将promethues-operator内嵌页面服务项目曝露在群集外,并规定应用30444端口号,指令如下所示:
这时在网页中键入Pod连接点所属的宿主机IP 端口地址,URL实例如下所示:
这时就可以见到Promethues内嵌的监管数据可视化页面了,实际效果如下图所示:
而假如这时以PromeQL的方法查询一个实际指标值,以“http_requests_total”为例子,展现实际效果如下图所示:
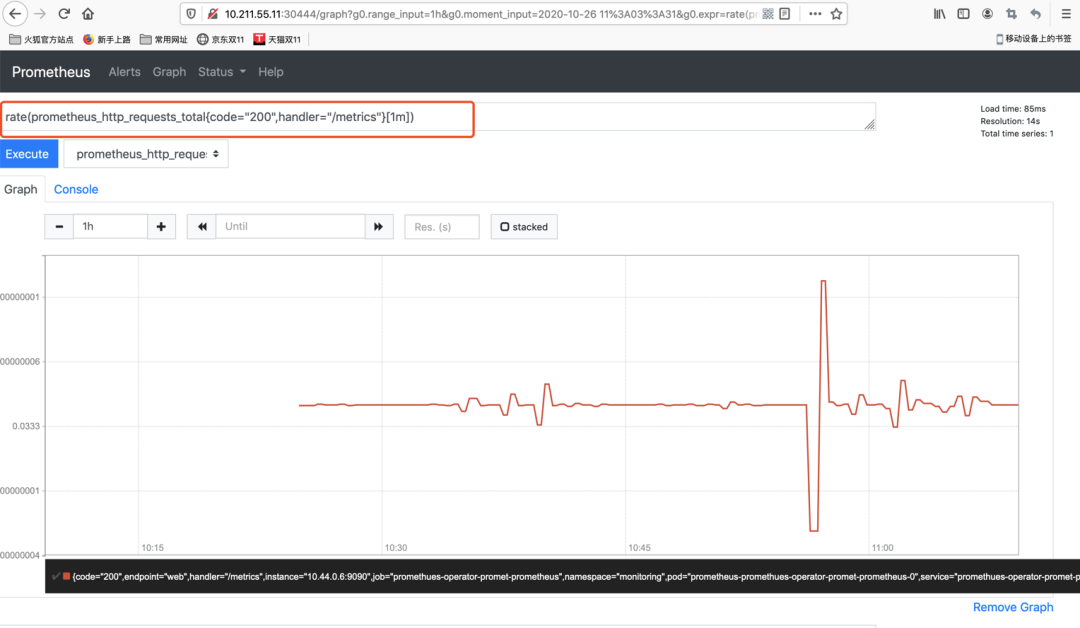
从而表明,这时Promethues监控系统早已运行,并收集了有关Metrics指标值数据信息!
Grafana数据可视化监控系统
Grafana是一个强悍的混合开发的开源系统衡量剖析和数据分析工具,可以将收集的指标值信息开展订制化的用户界面展现,常常被用做为时间序列分析数据信息和应用软件剖析的数据可视化。Grafana适用多种多样数据库,如InfluxDB、OpenTSDB、ElasticSearch及其Prometheus。
前边我们在Kubernetes中安裝布署Prometheus-Operator时,事实上Grafana就早已被集成化并运作了,可以根据Kubernetes的有关指令查看Grafana的真实运作Pod,并将其Web端口对外开放开展曝露,详细如下:
#查询服务项目连接点信息内容kubectl -n monitoring get svc#应用nodeport方法将promethues-operator-grafana曝露在群集外,特定应用30441端口号kubectl patch svc promethues-operator-grafana -n monitoring -p '{"spec":{"type":"NodePort","ports":[{"port":80,"targetPort":3000,"nodePort":30441}]}}'
必须留意因为Grafana的运用运作的默认设置端口号为80,为防止试验自然环境矛盾,这儿投射时将总体目标器皿端口号特定为3000,并最后将连接点端口映射为30441。进行后,电脑浏览器键入URL:
#IP地址为投射指令实行时所处的连接点http://10.211.55.11:30441
假如投射一切正常,这时会回到Grafana数据可视化用户界面的登录界面,如下图所示:
这儿缺省登陆账户密码为:admin/prom-operator。键入后可进到Grafana主界面如下图所示:
能够看见布署进行的Grafana早已默认设置内嵌了很多对于Kubernetes平台的私有云监管Dashboard,例如对于Kubernetes集群部件的“Kubernetes/API server”、“Kubernetes/Kubelet”,及其对于Kubernetees存储资源的“Kubernetes/Compute Resources/Pod”、“Kubernetes/Compute Resources/Workload”这些。
这儿大家找一个对于Kubernetes物理学连接点的“Nodes”监管Dashboard,点击打开后见到的监管实际效果如下图所示:
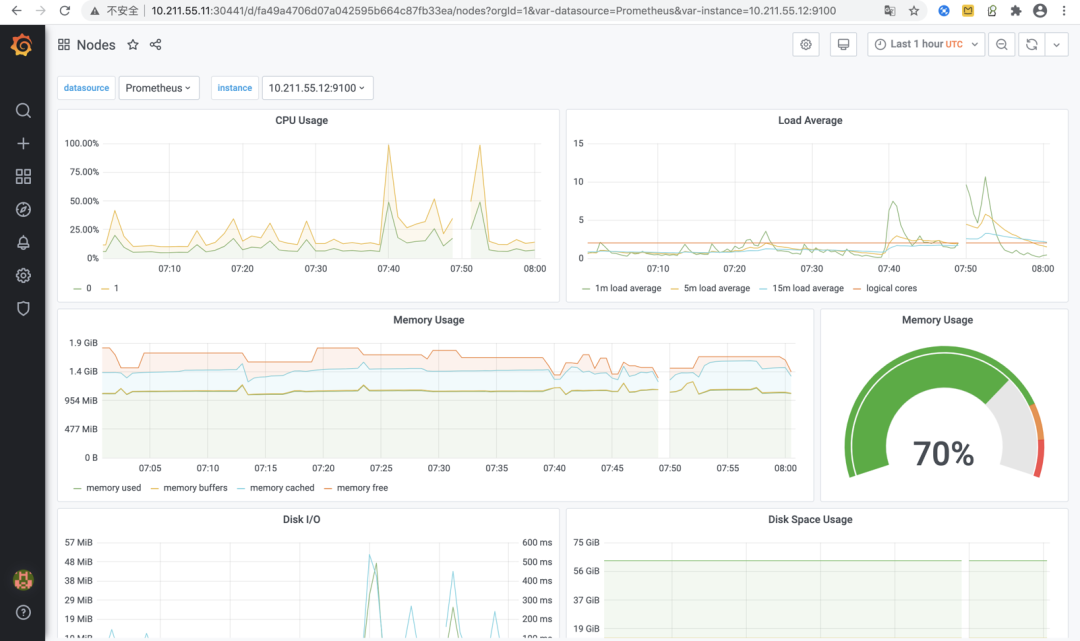
图中所显示的Dashboard中展现了Kubernetes集群所属的各物理学连接点CPU、负荷、运行内存、硬盘I/O、储存空间、数据传输等硬件设备的运用状况。从那些丰富多彩的主视图可以看得出Grafana强劲的监管指标值数据可视化工作能力!
续篇
文中给我们从概念到实践活动简易讲解了Kubernetes微服务架构监管机制的搭建流程,期待能对大伙儿学习培训Kubernetes有一定的协助。现阶段以Kubernetes为代表的容器化技术性现已成为了当代应用软件公布的规范方法,作为一名一般研发人员,对Kubernetes的了解将有利于大家更深层次的了解总体系统软件的搭建原理,也是大家升阶提高不可或缺的知识储备!
全文连接:https://mp.weixin.qq.com/s/WbkoqOnCQv0cywPysfKzng